軟件學院趙生捷團隊聯合上海人工智能實驗室發布首個大模型因果推理評測體系CaLM
來源:軟件學院
時間👨👨👧👧:2024-05-27 瀏覽:
近日,恒达平台軟件學院趙生捷教授團隊聯合上海人工智能實驗室(上海AI Lab)🎳、上海交通大學👨🔬、北京大學及商湯科技發布首個大模型因果推理開放評測體系及開放平臺CaLM(Causal Evaluation of Language Models)。首次從因果推理角度提出評估框架🫴🏿🧜🏿♀️,為AI研究者打造可靠評測工具🧖🏼♂️,從而為推進大模型認知能力向人類水平看齊提供指標參考。

因果推理是人類認知能力最重要的特征之一,提升因果推理能力被視為由機器智能邁向人類智能水平的關鍵步驟。為對大模型進行科學有效的因果推理能力評估🏊🏼♂️,趙生捷教授聯合團隊在CaLM中提出包含因果評估目標(Causal Target)👏🏼、評估方式(Adaptation)😢、評估標準(Metric)及錯誤分析(Error)的評估框架,同時構建了超過12萬道題目的中英文數據集。基於CaLM🐁,聯合團隊首次對28個當前主流大模型進行了因果推理能力評測,共產生了50項實證性發現🤴🏼。
CaLM采用了一套靈活🐉、易擴展的評估框架🤜🏼,並按照預設實施順序進行評測:因果評估目標(Causal Target)→評估方式(Adaptation)→評估標準(Metric)→錯誤分析(Error)。CaLM的評估框架設計與實施流程,還可應用於數學推理🧘🏽♀️、專業知識及長文本處理等模型能力評估體系構建。
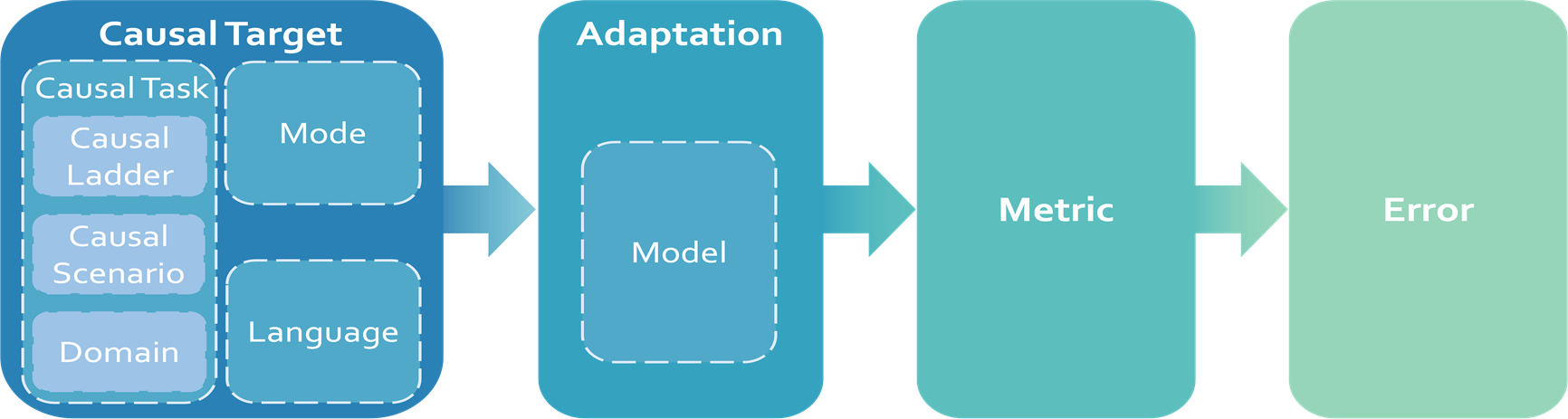
CaLM評估框架
在當前普遍采用的Judea Pearl提出的因果階梯理論基礎上👩🏻🚀,CaLM進一步發展並明確了四個層次的因果任務:因果發現(Causal Discovery)、關聯(Association)🏄🏻♀️、幹預(Intervention)及反事實(Counterfactuals)。每層次任務按復雜程度進行基礎到高級的順序排列,構成了自下而上的框架。
因果發現旨在從數據或語義中推測出潛在的因果結構,關聯探索數據間的統計依賴關系,幹預預測有意改變環境中的變量所帶來的影響,以及反事實則對假設的替代場景進行推理。針對四個任務層次🧙🏿,CaLM設計了因果歸因👈🏽、解釋移除效應🕡、對撞偏差和反事實推理等21種因果場景,覆蓋COPA🧝🏻、CLADDER及CaLM-IV等多種數據集和問題類型🏋️♂️。
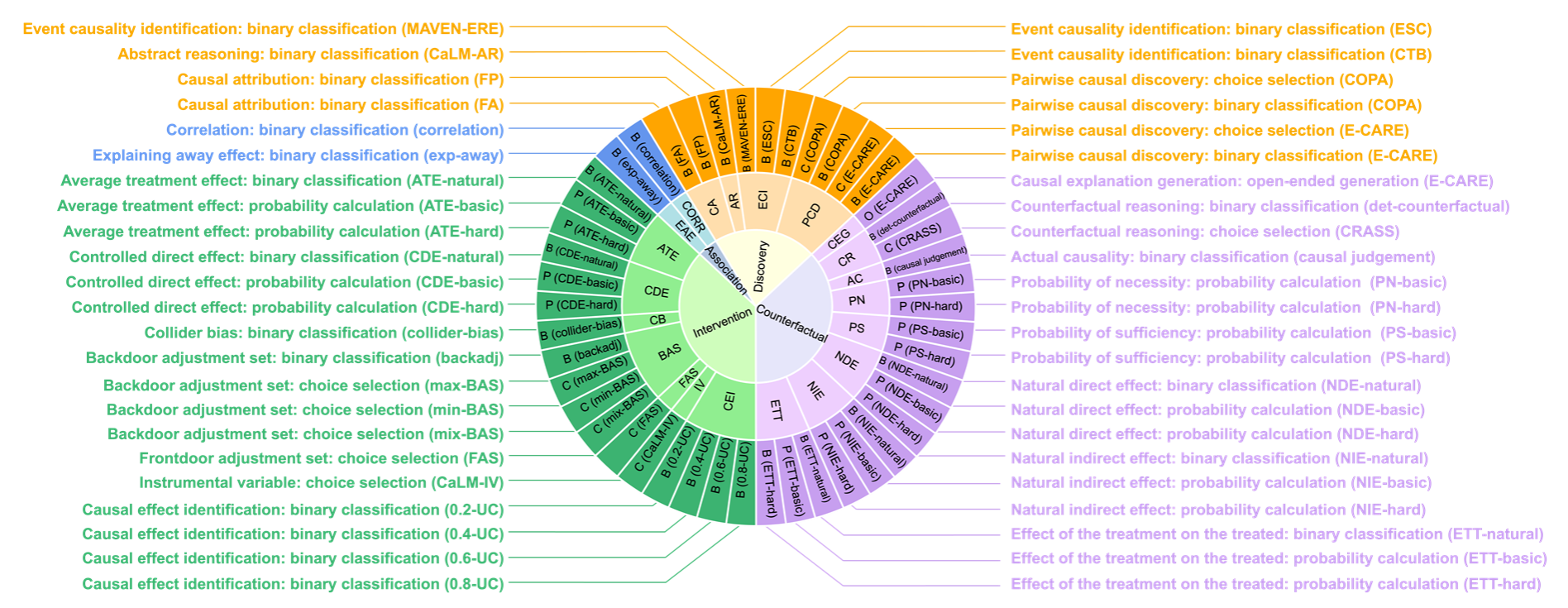
CaLM因果評估目標設置
在評估方式的選擇上,CaLM采用基準提示、對抗性提示、思維鏈及上下文學習等9種評估方式。綜合考量了評測實踐過程的受眾廣泛性🤞🏻、用戶易用性以及實驗控製性。針對模型、提示詞以及因果場景,CaLM中分別設置了不同的評估標準🧜🏼,覆蓋包括準確率🧗🏻♂️🚮、魯棒性、理解度等7種🧑💼,全面反映模型的因果推理能力和魯棒性、提示詞有效性。越復雜的因果場景模型越難解決,從而該場景成熟度越低🫸🏻,因此CaLM同時設置了考察因果場景成熟度的評估標準👈🏼。
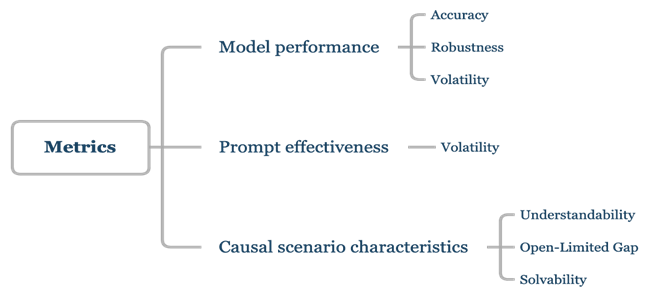
CaLM評估標準
聯合團隊認為👍🏻,大模型評測中產生的錯誤,是應用於下一階段研究的寶貴資源。通過發現並定義錯誤,研究人員能夠更清晰地界定模型能力邊界👦🏻,識別模型存在的缺陷🙆🏇🏿,並尋找對應提升路徑。為此,CaLM在評估過程中,將模型產生的錯誤系統地分為兩大類:定量錯誤(Quantitative)和定性錯誤(Qualitative)。不僅對每類錯誤進行明確的定義,還對所有定量錯誤都進行了統計分析,以量化錯誤的頻率和模式。CaLM也對於所有定性錯誤進行了深入的案例研究🧬,以理解錯誤的具體情況和成因。
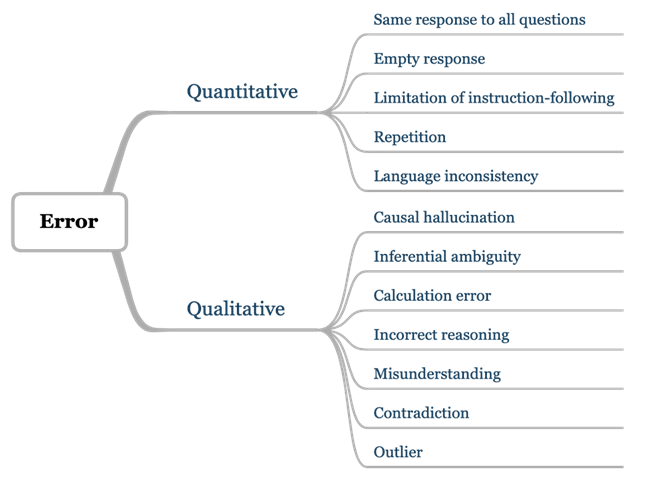
CaLM錯誤結果分析框架
為了使因果推理能力評估有“考題”可循🙋,聯合團隊構建了一套全新的評測數據集。基於四個層級的因果任務設置📜,涵蓋了豐富的因果概念🔊,包含超過12萬條中英文數據🧑🍳。同時,研究人員還細致地將文本模態劃分為日常表達(Natural)、抽象表達(Symbolic)和數學表達(Mathematical)三種子態,以考察模型在不同類型模態下的理解能力🏌🏿。該數據集90%的內容為全新構建🤵🏿🐡,10%來自於現有公開數據集🤯🧑🏿💼,既能與已有公開結果進行對比,反映評估的有效性,又能避免訓練集數據汙染問題👰🏼♀️。
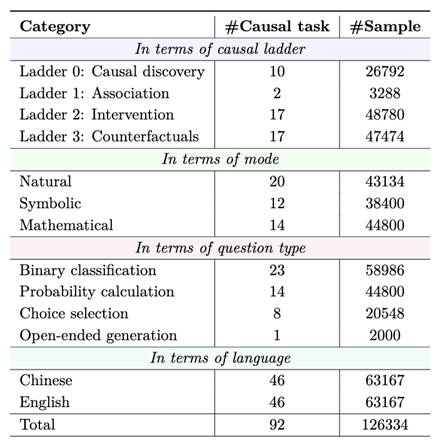
CaLM數據集問題類型統計概覽
針對28個當前主流大模型🚴♀️,聯合團隊使用了CaLM進行因果推理能力評測,共產生了50項實證性發現。評估數據和可視化結果均已發布至CaLM項目主頁(https://opencausalab.github.io/CaLM/),同時CaLM數據集、評估流程和錯誤分析的全流程均已開源(https://github.com/OpenCausaLab/CaLM),便於產學界自主研究使用。(張晶)
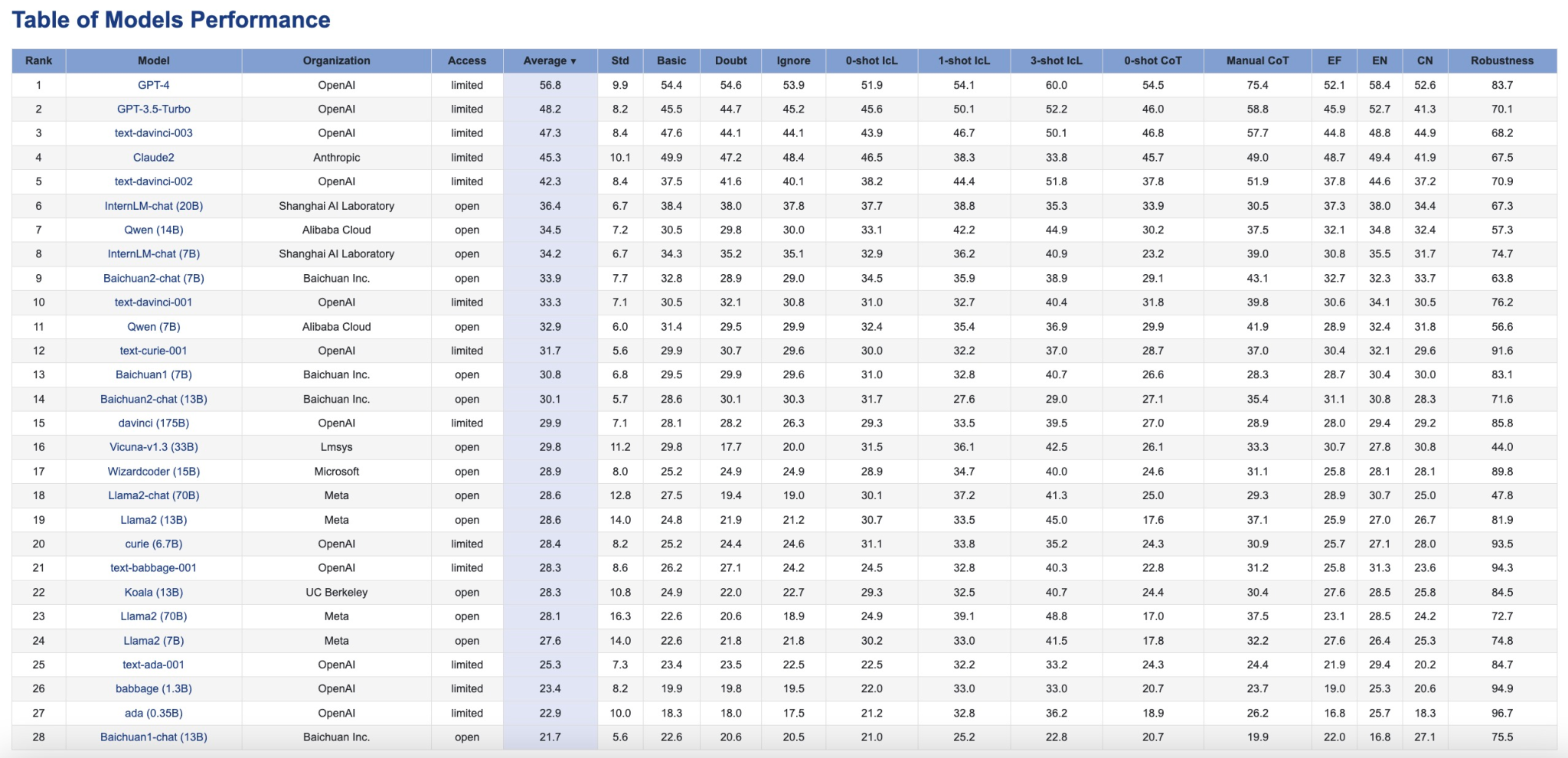
CaLM評估結果
論文鏈接:https://arxiv.org/pdf/2405.00622



